A classic problem in relational databases. I see this come up again and again. SQL report writers in my department will be stumped when the query they setup for a reporting services report using parameters will run really fast in testing and then be very slow when a specific set of parameters are selected.
SQL Internals Recap
To set the scene we need to be able to describe and understand at a high level what happens when a query is executed on a SQL Server database. When a query is submitted to the database a number of steps take place within the engine:
- The query is checked to ensure it has the correct syntax;
- The query is checked to ensure the database structures (tables, columns, views etc) exist and the executor has sufficient permissions to access them;
- The plan cache in the buffer pool is checked to see if the query which is being executed exists there;
- If the query is not in the plan cache the database optimiser will create an execution plan;
- If the query is in the plan cache the execution plan which has already been made will be used. This avoids using CPU time to create a new execution plan.
To determine if a query is already in the plan cache a hash value will be calculated against the query text and compared to the cache. That means a small change to the text of a query will result in a new execution plan being added to the plan cache. Note the actual method is more complex but this definition provides a simplistic explanation for our purposes.
Similar Queries
Let’s think about an OLTP system such as a Hospital Patient Record system where 100’s of people are searching for patients each day. In the background the queries being executed against the database for these searches will be very similar.
We can replicate an example of this using one of the StackOverflow databases with the Users table. The query to get information about a user is below. We will write 2 queries to get 2 different users. The queries do exactly the same thing except look for different users. Note the queries were executed on pre SQL Server 2019 compatibility levels.
USE StackOverflow2010
GO
SELECT * FROM dbo.Users WHERE Id = 1;
SELECT * FROM dbo.Users WHERE Id = 10;
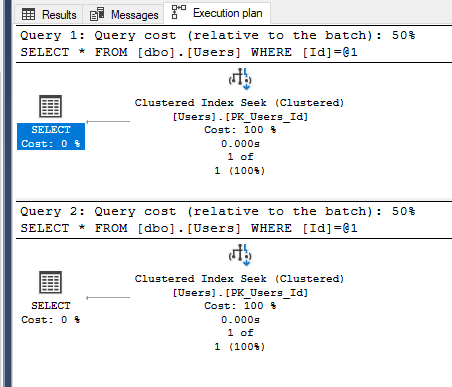
The queries generate the same shape of plan; a seek is performed against the clustered index to retrieve the record for the userid specified. Because the query text of the statements are different as we have used literals for the different values we could be generating different plans. This can bloat our plan cache and actually force other plans to be removed due to memory restrictions forcing them to be recompiled if run again. The reason I say it “could” rather than “will” is because SQL Server is much smarter than we are giving it credit for than the simple explanation we gave and can actually trivialise these types of statements to not do that!
Parameterisation
With parameterisation we can bring in query reuse for these statements. The literal value gets replaced with a parameter and the text of the query stays the same. This can stop similar plans being added into the plan cache and is what happens with stored procedures. The below query would only get added once into the cache when run from the same database instance with the same SET settings.
SELECT * FROM dbo.Users WHERE Id = @id;
SELECT * FROM dbo.Users WHERE Id = @id;
Parameter Sniffing
When the query gets executed the fist time it is placed in the plan cache with the parameters that were used in that call. The parameter is sniffed from the original call. Subsequent executions are based upon these parameters and the same execution plan is used. This is good news in general as recompiling queries takes CPU cycles. It is also good where data distribution is uniform; in our original example this was the case; a UserId will either bring back 1 or 0 records as it is the primary key. The original execution plan generated with be suitable for any parameter value used. However if data is skewed we can run into big problems.
Problems
Let’s look at another example with the Stackoverflow dataset. This time let’s focus on comments and reputation points. We are going to run a query which counts the number of comments made by users who pass a reputation point threshold. The first query will look for users who have a very large reputation score which will qualify only a very few users. The second query the threshold will be greater than 0; this will include a lot of different users. The rest of the query will be the same. We will also add a couple of indexes to help the query. We will show the execution plan to see what the database has decided to do for each query. Note, at this stage we have not used parameters, only literal values.
CREATE INDEX ix_user_repuation on dbo.users (Reputation);
CREATE INDEX ix_comments_userId ON dbo.Comments (UserId);
SELECT COUNT(*)
FROM dbo.comments c
INNER JOIN dbo.Users u on c.UserId = u.Id
WHERE u.Reputation > 1000000
SELECT COUNT(*)
FROM dbo.comments c
INNER JOIN dbo.Users u on c.UserId = u.Id
WHERE u.Reputation > 0
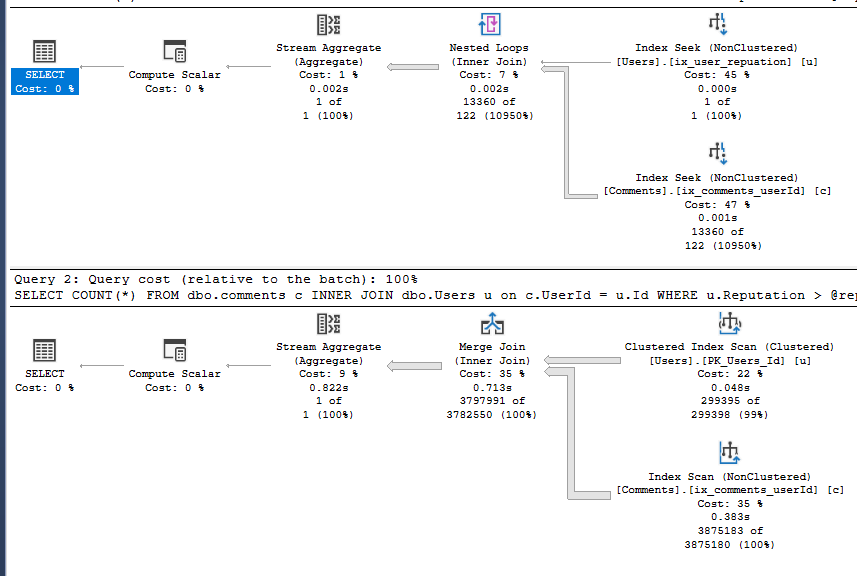
The shape of the 2 plans is now different due to the difference in the row estimates coming back based upon the reputation score threshold we supplied. In the first query the database estimates 1 row (which was right) which results in the database doing a nested loop join between the Users and Comments tables. A nested loop join is good when one side of the join has a low number of rows which is the case here. The second query uses a merge join instead of a nested loop join. The estimated rows coming back from the Users table is much higher this time, 99% of the table so this type of join is more applicable here. This shows the database optimiser at work using statistics to generate an optimal plan each time.
Let’s put this query into a stored procedure which has a parameter we can pass it to define the reputation point threshold and see what changes.
CREATE OR ALTER PROCEDURE #getCommentCountForReputation
@reputationScore int
AS
BEGIN
SELECT COUNT(*)
FROM dbo.comments c
INNER JOIN dbo.Users u on c.UserId = u.Id
WHERE u.Reputation > @reputationScore;
END;
Let’s start by running the procedure with a reputation threshold of 0 and then running it again for a reputation score of 1000000.
SET STATISTICS IO ON;
EXECUTE #getCommentCountForReputation @reputationScore = 0;
EXECUTE #getCommentCountForReputation @reputationScore = 1000000;
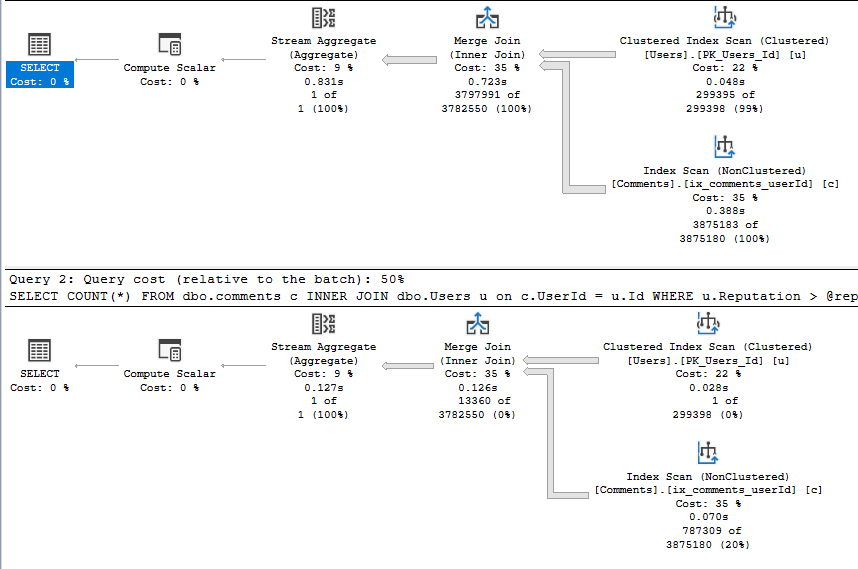
This time both execution plans are the same. Because we are now using parameters the execution plan gets based upon the parameter used the first time – 0 in this case. When we run the procedure the 2nd time even though we pass a value of 1000000 is still uses the 0 value. If we look at the XML of the execution plan we can see this. It shows the ParameterCompiledValue is 0.

Let’s free the plan cache using the FREEPROCCACHE command (don’t do this on your production server!) and execute the procedure twice again, but this time in the opposite order.
DBCC FREEPROCCACHE;
GO
EXECUTE #getCommentCountForReputation @reputationScore = 1000000;
EXECUTE #getCommentCountForReputation @reputationScore = 0;
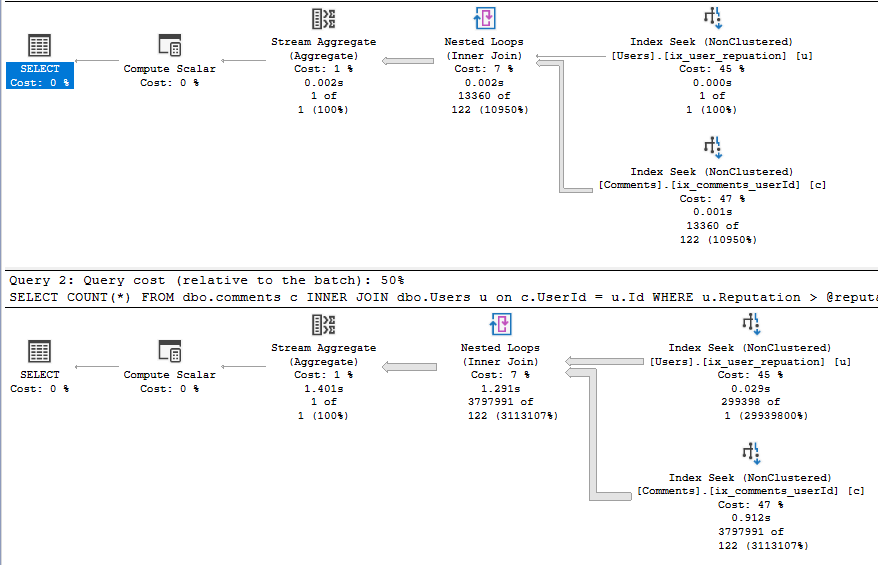
Again both queries have the same execution plan but the shape has changed. The plans are now based on the first parameter used which is now 1000000. The nested loop join, which works well when one side of the join has a small dataset now has a large dataset on both sides which can effect performance. We can see the ParameterCompiledValue has changed in the XML.

To quantify this change let’s take a look at the number of logical reads occurring between the different execution plans. Logical reads denotes the number of 8KB pages that are read to retrieve the data from a table.
If we look at the number of logical reads against the Comments table when the parameter @reputationScore = 0 is passed and the cached parameter value is = 0.

The comments table had 1,389 logical reads. Let’s compare this to the execution plan for the same parameter value but when the cached parameter value is 1000000.

The comments table has now done 905, 771 logical reads, an increase of 652x. With a suboptimal plan caused by parameter sniffing we are now doing a huge amount more work which can increase the run time of the query. In the real world this can mean queries which took seconds with one parameter value can take minutes with another.
Workarounds
There are a number of options available to you as a developer which can help (or not help) deal with the parameter sniffing side effects.
Local Variables
We have the option to add in local variables to the stored procedure, assign incoming parameters to the local variables and use them in the query. The value of local variables are not known at runtime so the database defaults back to a default process using statistics based upon the density vector. Let’s change the query to use local variables and see what happens.
DROP PROCEDURE #getCommentCountForReputation;
GO
CREATE PROCEDURE #getCommentCountForReputation
@reputationScore int
AS
BEGIN
DECLARE @localVariable AS int;
SET @localVariable = @reputationScore;
SELECT COUNT(*)
FROM dbo.comments c
INNER JOIN dbo.Users u on c.UserId = u.Id
WHERE u.Reputation > @localVariable;
END;
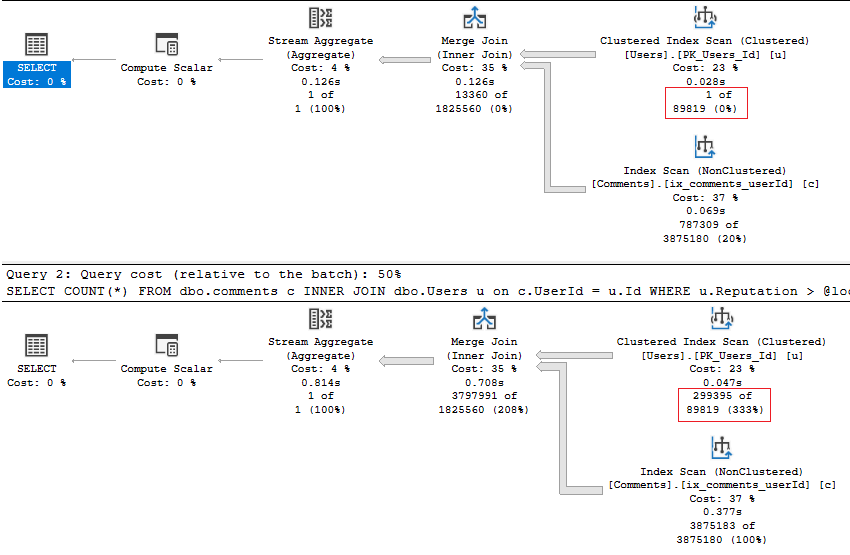
We get the same shape plan on both executions. Both plans are estimating 89,819 rows to come back for the user tables. We will get the same row estimates back whatever value we pass in. Instead of using the parameter passed in the first time the query was put into the plan cache it now gets based upon an average plan. An average plan could be good but also could be bad. This is the same as using the OPTIMIZE FOR UNKNOWN command.
If we change the procedure to explicitly use OPTIMIZE FOR UNKNOWN then we get the same shape plan and estimated row number coming from the users table.
DROP PROCEDURE #getCommentCountForReputation;
GO
CREATE PROCEDURE #getCommentCountForReputation
@reputationScore int
AS
BEGIN
SELECT COUNT(*)
FROM dbo.comments c
INNER JOIN dbo.Users u on c.UserId = u.Id
WHERE u.Reputation > @reputationScore
OPTION (OPTIMIZE FOR UNKNOWN);
END;
DBCC FREEPROCCACHE;
GO
EXECUTE #getCommentCountForReputation @reputationScore = 1000000;
EXECUTE #getCommentCountForReputation @reputationScore = 0;

Option Recompile
The OPTION RECOMPILE command tells the database to create a brand new execution plan even if one is in the plan cache. This will ensure that the plan is executed based upon the parameters passed to it at the time. The downside is a new plan needs to be generated on each execution which requires the use of CPU cycles. If a specific query gets executed a lot this can be a problem. However for some queries it can be great; particularly queries driving reporting services reports with multiple parameters that change the shape of data easily.
Lets change our stored procedure to include the option recompile command and execute for 2 different parameters.
DROP PROCEDURE #getCommentCountForReputation;
GO
CREATE PROCEDURE #getCommentCountForReputation
@reputationScore int
AS
BEGIN
SELECT COUNT(*)
FROM dbo.comments c
INNER JOIN dbo.Users u on c.UserId = u.Id
WHERE u.Reputation > @reputationScore
OPTION (RECOMPILE);
END;
DBCC FREEPROCCACHE;
EXECUTE #getCommentCountForReputation @reputationScore = 1000000;
EXECUTE #getCommentCountForReputation @reputationScore = 0;
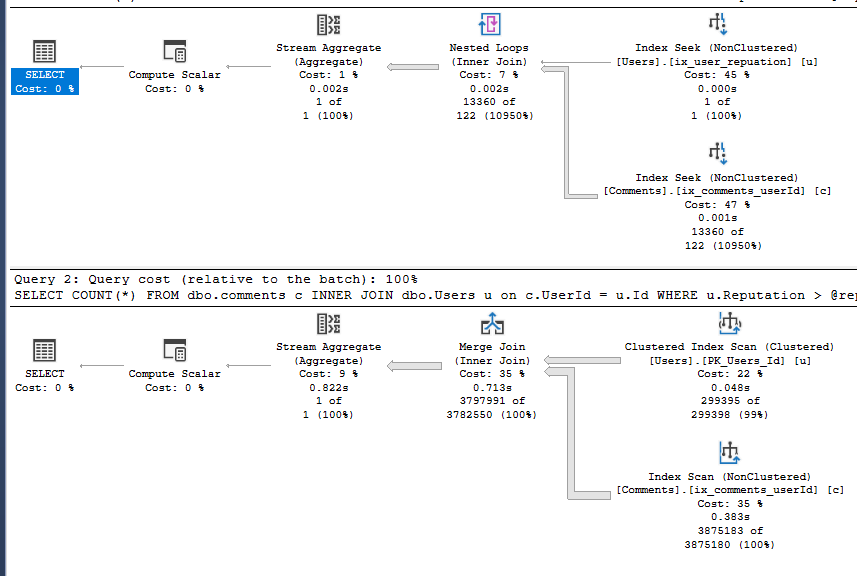
Each execution has now generated a different plan based on the parameter value passed in.
Optimize For
The OPTIMIZE FOR statement allows us to specify what parameter to use when caching the execution plan. This gives us the option of explicitly specifying it rather than being left with the parameter used the first time the query is run.
Let’s setup an example using this statement with the value of 10 for @reputationScore.
DROP PROCEDURE #getCommentCountForReputation;
GO
CREATE PROCEDURE #getCommentCountForReputation
@reputationScore int
AS
BEGIN
SELECT COUNT(*)
FROM dbo.comments c
INNER JOIN dbo.Users u on c.UserId = u.Id
WHERE u.Reputation > @reputationScore
OPTION (OPTIMIZE FOR (@reputationScore = 10));
END;
GO
We will run our usual 2 queries against the updated procedure and check the execution plans.
DBCC FREEPROCCACHE;
GO
EXECUTE #getCommentCountForReputation @reputationScore = 1000000;
EXECUTE #getCommentCountForReputation @reputationScore = 0;
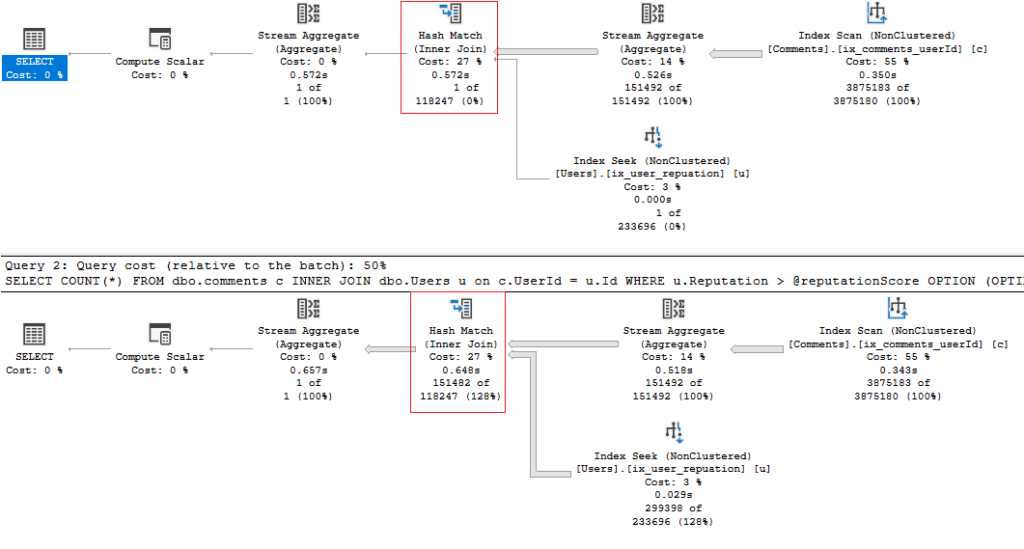
The 2 queries have generated the same plan. The plan generated is actually different from the previous 2 plans we have been seeing. We now see a Hash Match physical operator whereas before we saw either a Nested Loop or Merge Join. This is the plan optimised for a value of 10. If we look at the XML we can see the ParameterCompiledValue is set to 10.

If there is a parameter value which can provide a decent enough plan across all possibilities than this could be a reasonable choice. However it can be difficult to predicate how the shape of our data will change over time; something which is OK now may be unacceptable in the future.
Query Choices
We can use conditional logic to branch our executions based upon the values in the parameter. We can run different code when @reputationScore is low and when @reputationScore is high. Each one will generate a separate execution plan provided the code text differs. We will still have a parameter sniffing issue with each query but because we are limiting what parameter values hit each one we can narrow our problem window.
CREATE OR ALTER PROCEDURE #getCommentCountForReputation
@reputationScore int
AS
BEGIN
-- Run if the reputation score is low.
IF @reputationScore < 10000
BEGIN
SELECT COUNT(*)
FROM dbo.comments c
INNER MERGE JOIN dbo.Users u on c.UserId = u.Id
WHERE u.Reputation > @reputationScore
END
ELSE
-- Run if the reputation score is high.
BEGIN
SELECT COUNT(*)
FROM dbo.comments c
INNER LOOP JOIN dbo.Users u on c.UserId = u.Id
WHERE u.Reputation > @reputationScore
END;
END;
GO
Dynamic SQL
We can do something similar with dynamic SQL. Think of a scenario where there is a reporting service report with a number of parameters and the input of some of these parameters are optional. Dynamic SQL gives us the ability to build the query dependant on which parameters have been filled in. Like the query choice option we can generate different execution plans for the different parameters selected by the end user. Again this doesn’t remove the parameter sniffing issue but minimises the parameter combinations we are hitting.
Let’s setup a procedure which can take in a reputation score, location and last access date. Each of these parameters is optional.
CREATE OR ALTER PROCEDURE #getCommentCountForReputationLocationAccessDate
@debug bit = 0,
@reputationScore int = NULL,
@location nvarchar(100) = NULL,
@LastAccessDate datetime = NULL
AS
BEGIN
DECLARE @SQLStatement AS nvarchar(max);
-- add in formatting which makes the statement more readble if printed.
DECLARE @crlf nvarchar(2) = nchar(13) + nchar(10);
-- default SQL statement
SET @SQLStatement =
N'SELECT COUNT(*)' + @crlf +
N'FROM dbo.comments c' + @crlf +
N' INNER LOOP JOIN dbo.Users u on c.UserId = u.Id' + @crlf +
N'WHERE 1 = 1' + @crlf;
IF @reputationScore IS NOT NULL
BEGIN
SET @SQLStatement = @SQLStatement + N' AND u.Reputation = @reputationScore' + @crlf;
END
IF @location IS NOT NULL
BEGIN
SET @SQLStatement = @SQLStatement + N' AND u.location = @location' + @crlf;
END
IF @LastAccessDate IS NOT NULL
BEGIN
SET @SQLStatement = @SQLStatement + N' AND u.LastAccessDate > @LastAccessDate' + @crlf;
END
-- Option to run in debug mode where we can print the statement to the screen.
IF @debug = 1
BEGIN
PRINT @SQLStatement;
END
-- Execute the dynamic statement.
ELSE
BEGIN
EXECUTE sp_executesql @SQLStatement,
N'@reputationScore int, @location nvarchar(100), @LastAccessDate datetime',
@reputationScore, @location, @LastAccessDate;
END;
END;
We use dynamic SQL to construct the SQL statement we are going to run. We create the WHERE clause based upon what parameters are filled in. If they are missing then they do not get included in the statement.
I have added a debug mode which will print out the SQL statements we are going to run rather than executing them. Let’s execute them with 3 different parameter options.
EXECUTE #getCommentCountForReputationLocationAccessDate @debug= 1, @reputationScore = 90;
EXECUTE #getCommentCountForReputationLocationAccessDate @debug= 1, @reputationScore = 100, @location = 'United Kingdon';
EXECUTE #getCommentCountForReputationLocationAccessDate @debug= 1, @location = 'United Kingdom', @LastAccessDate = '2009-08-30 20:56:23.897';

The WHERE clause of each statement is different. The rest of the query stays the same. Because the 3 queries are different they will generate 3 different execution plans into the cache.
One of the possible issues with dynamic SQL is if we do not use parameters we will generate a very large number of different execution plans which will fill up the plan cache. We do this by defining our parameters in the sp_executesql statement. If the parameters are appended directly into the string they will become literals.
If we run 2 of the queries we will see they generate 2 different execution plans.
EXECUTE #getCommentCountForReputationLocationAccessDate @reputationScore = 90;
EXECUTE #getCommentCountForReputationLocationAccessDate @reputationScore = 100, @location = 'United Kingdom';

SQL Server newer versions – Adaptive Joins
Adaptive joins attempt to overcome execution plan problems where estimated row counts are off, like what we can see with parameter sniffing when the shape of data for parameter values can be very different.
Adaptive joins were brought in from SQL Server 2017, but only worked for queries with column store indexes. In 2019 they became available to other queries. Adaptive joins allow a physical join operator to be determined at runtime based upon a threshold number of rows coming out of the table. It can choose between using a nested loop or hash match operator. If we change our compatibility level to 150 (SQL Server 2019) and run the following we get see an adaptive join in action.
CREATE OR ALTER PROCEDURE #getCommentCountForReputation
@reputationScore int
AS
BEGIN
SELECT COUNT(*)
FROM dbo.comments c
INNER JOIN dbo.Users u on c.UserId = u.Id
WHERE u.Reputation > @reputationScore
END;
DBCC FREEPROCCACHE;
EXECUTE #getCommentCountForReputation @reputationScore = 10;
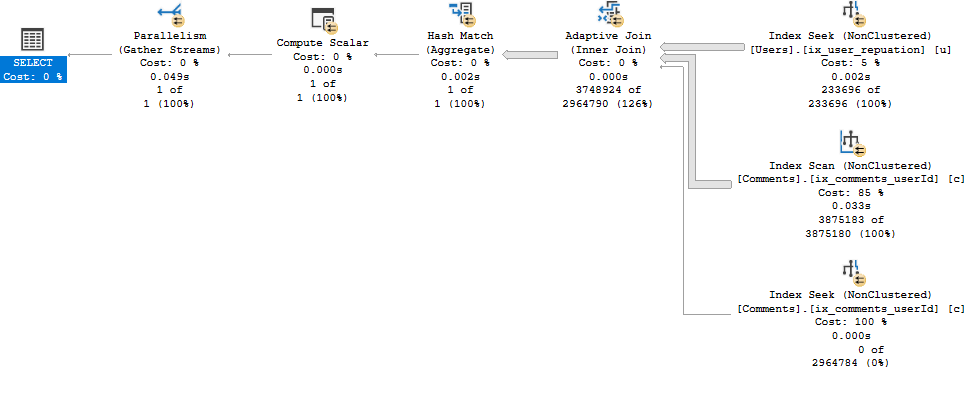
- SQL Server did a seek using the non-clustered index ix_user_reputation on the users table.
- It joins to the comments table using the non-clustered index ix_comments_userId. However with the adaptive join it has two options; a seek or a scan.
- The use of the scan or seek is determined by the threshold, which can be seen by hovering over the Adaptive Join operator in the execution plan. In this case the threshold was 22, 274.5 rows. As this threshold was exceeded a scan was used and the adaptive join has did a hash match, which can be seen in the execution plan. If it was below this threshold than a seek would have been used.
Let’s run our procedure again but with a reputation score of 10, 000.
EXECUTE #getCommentCountForReputation @reputationScore = 10000;
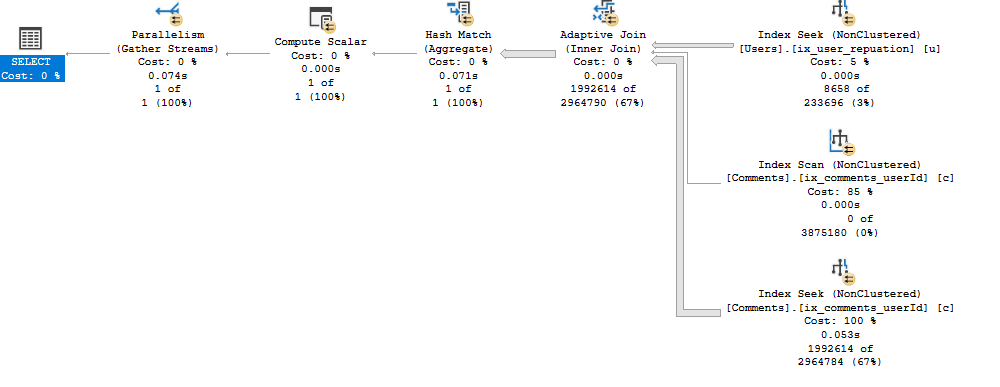
This time the number of rows coming out of the seek on the users non-clustered index was below the threshold so a seek is done on the comments table. The adaptive join has now used a nested loop.
Final Thoughts
When creating procedures where the parameters can vary the shape of the data coming back greatly be conscious of the effects of parameter sniffing and remember to test the queries across a number of different parameter combinations. If query tuning is needed then think about the options outlined in this article weighing up the advantages and disadvantages of each to see if they can make a difference.